Вовед во анализа на сложеност на алгоритми
Dionysis "dionyziz" Zindros <dionyziz@gmail.com>Преведено од Драган Димковиќ <d.gago7@hotmail.com>
Преведено од Кристина Гогова <kristina.gogova@yahoo.com>
- English
- Ελληνικά
- македонски
- Español
- Nederlands
- עברית
- Português
- srpskohrvatski
- Українська
- Русский
- Help translate
Вовед
Многу од програмерите кои го прават најатрактивниот и најкорисниот софтвер денеска, како на пример, многу од работите кои ги гледаме на Интернет или ги користиме секојдневно, не се добро “потковани” со теоретска информатика. Тие се, сепак, одлични и креативни програмери и им благодариме за тоа што го прават.
Но, теоретската информатика си има своја примена и може да излезе дека е доста практична. Во оваа статија, наменета за програмери кои си ја знаат својата работа, но немаат теоретски основи од информатика, ќе ви ги претставам едни од најкорисните алатки во информатиката: -нотацијата “Големо О” и анализата на сложеноста на алгоритми. Како за некој што работел и во услови на академска информатика и во производствено ниво на развој на софтвер, ова е алатката која се покажа дека е навистина корисна во пракса, па се надевам дека откако ќе ја прочитате оваа статија, ќе можете да ја употребите во својот код за да го подобрите. Откако ќе го прочитате овој пост, би требало да ги разберете секојдневните термини кои информатичарите ги користат како “Големо О”, “асимптотско однесување” и “анализа на најлош случај”.
Овој текст е наменет и за учениците од 5-то до 8-мо одделение и за средношколците од Грција или од каде било кои се натпреваруваат во Интернационалната Олимпијада по Информатика , алгоритамски натпревар за студенти, или какви било други слични натпревари. Како таков, нема никакви математички предуслови и ќе ви ја даде основата која ви е потребна за изучување на алгоритмите со потемелно разбирање на теоријата зад нив. Како некој што се натпреварувал во овие студентски натпревари, искрено ви препорачувам да го прочитате целиот воведен материјал и да пробате целосно да го разберете, затоа што тоа ќе биде неопходно како што ќе ги изучувате алгоритмите и како што ќе учите понапредни техники.
Мислам дека овој текст ќе биде корисен за индустриските програмери кои немаат многу искуство со теоретска информатика(факт е дека некои од најинспиративните софтверски инженери никогаш не запишале факултет). Но, затоа што е и за студенти, може понекогаш да наликува на учебник. Понатаму, некои од насловите во овој текст може да ви изгледаат премногу лесни, на пример, можеби сте ги сретнале за време на учебните години. Ако мислите дека ги разбирате, може да ги прескокнете. Други секции одат подлабоко и стануваат потеоретски, бидејќи студентите кои учествуваат во овој натпревар мораат да знаат малку повеќе за теоретските алгоритми, за разлика од обичниот практикант. Но, овие работи се добри да се знаат и не се толку тешки за да разберат, па затоа вредат за вашето време. Бидејќи оригиналниот текст е наменет за средношколци, не е потребна никаква математичка основа, така што било кој со малку програмерско искуство( на пример, ако знае што е рекурзија(анг. recursion)) ќе може да разбере без проблем.
Низ оваа статија, ќе најдете многу линкови кои водат до интересен материјал, најчесто надвор од темата за која дискутираме. Ако сте индустриски програмер, најверојатно ќе ви бидат познати овие концепти. Ако сте помлад студент кој учествува во натпревари, следењето на овие линкови ќе ви даде патоказ до други области од информатиката и софтверското инженерство кои можеби досега не сте ги истражиле и кои може да ги погледнете за да си ги проширите интересите.
Нотацијата “Големо О” и анализата на сложеноста на алгоритми е нешто што на голем број на индустриски програмери како и помлади студенти им е тешко да го разберат, се плашат, или ги избегнуваат сметајќи ги за непотребни. Но не е толку тешко или теоретско како што отпрвин изгледа. Сложеност на алгоритми е само начин формално да се измери колку брзо една програма или алгоритам се извршува, така што е доста прагматичен. Да почнеме со мала мотивација.

Мотивација
Веќе знаеме дека постојат алатки кои мерат колку брзо една програма се извршува. Има програми наречени профилери(анг. profilers) кои го мерат времето на извршување во милисекунди и можат да ни помогнат да го оптимизираме нашиот код со забележување на т.н “тесни грла” . Ова е корисна алатка, но не е значајна за сложеноста на алгоритмите. Сложеност на алгоритми е нешто дизајнирано за да се споредат два алгоритма на ниво - игнорирајќи не толку значајни детали како имплементацискиот програмски јазик, хардверот на кој алгоритмот се извршува, или пак инструкциското множество на дадената ЦПЕ(анг. CPU). Сакаме да споредиме алгоритми такви какви што се: Идеи како нешто е пресметано. Броењето на милисекунди нема да ни помогне во тоа. Можно е лош алгоритам напишан во програмски јазик од ниско ниво како што е асемблер (анг. assembler) , да се изврши многу побрзо отколку некој добар алгоритам напишан во програмски јазик од високо ниво како што е Python илиRuby. Затоа, време е да дефинираме што е тоа “подобар алгоритам”.
Бидејќи, алгоритмите се програми кои само извршуваат сметање, а не други работи што најчесто ги прават компјутерите, како што се мрежни задачи, влез или излез, анализата на сложеноста ни овозможува да измериме колку е брза програмата кога извршува пресметки. Примери за операции кои се чисто сметачки вклучуваат нумерички операции со подвижни запирки како што се собирање и множење; пребарување на база на податоци која е во меморија со случаен пристап(анг. RAM) за дадена вредност; пронаоѓање на пат кој ликот со вештачка интелигенција треба да го помине во видео игра така што да го помине најкраткиот пат во рамките на нивниот виртуелен свет(види Фигура 1); или извршување на подудирање на шема зададена со регуларен израз врз стринг(анг. string). Јасно е дека сметањето е сеприсутно во компјутерските програми.
Анализата на сложеноста е исто така алатка која ни овозможува видиме како еден алгоритам ќе се однесува како што влезните информации ќе стануваат поголеми. Ако пробаме со различен влез, како ќе се однесува алгоритмот? Ако на нашиот алгоритам му треба 1 секунда за да се изврши за влез со големина 1000, како ќе се однесува ако ги дуплираме влезните вредности? Дали ќе се извршува за исто време, за пола време поспоро, или пак 4 пати поспоро? Во практичното програмирање, ова е важно бидејќи ни овозможува да предвидиме како ќе се однесува нашиот алгоритам кога влезните податоци ќе станат поголеми. На пример, ако сме направиле алгоритам за веб апликација која работи добро со 1000 корисници и го измериме нејзиното време на извршување, користејќи ја анализата на сложеноста на алгоритми може да имаме доста јасна идеја што ќе се случи ако стигнеме до бројката од 2000 корисници. За алгоритамските натпревари, анализата на сложеноста ни дава увид во тоа колку долго нашиот код ќе се извршува за најголемите тест-случаи кои се користат за да ја тестираат коректноста на нашата програма. Така што, ако сме измерила како нашата програма ќе се однесува за мал влез, може да добиеме добра идеја за тоа како ќе се однесува за поголеми влезови. Да почнеме со едноставен пример: Наоѓање на најголемиот елемент во една низа.
Броење на инструкции
Во оваа статија, ќе користам различни програмски јазици како примери. Но, не се разочарувајте ако не го знаете дадениот програмски јазик. Бидејќи знаете да програмирате, би требало да можете да ги прочитате примерите без проблем дури и да не ви е познат дадениот програмски јазик, бидејќи тие ќе бидат едноставни и нема да користам никакви езотерични јазични карактеристики. Ако сте студент кој се натпреварува во алгоритамски натпревари, најверојатно ќе работите со C++, така што не би имале проблем да следите. Во тој случај предлагам да ги работите вежбите во С++.
Најголемиот елемент во една низа може да се најде користејќи едноставен дел од код како што е делот од Javascript кодот. За дадена влезна низа A со големина n:
var M = A[ 0 ];
for ( var i = 0; i < n; ++i ) {
if ( A[ i ] >= M ) {
M = A[ i ];
}
}
Сега, првата работа што треба да ја направиме е да изброиме колку фундаментални инструкции овој дел од код извршува. Ова ќе го направиме само еднаш и нема да биде потребно како што ќе ја развиваме нашата теорија, затоа издржете со мене во следниве моменти. Како што анализираме овој дел од код, сакаме да го поделиме во едноставни инструкции; работи кои можат да бидат извршени директно на ЦПЕ, или блиску до тоа. Да претпоставиме дека нашиот процесор може да ги изврши секоја од следните операции во посебна инструкција:
- Додели вредност на променлива
- Барај ја вредноста на дадениот елемент во низа
- Спореди 2 вредности
- Зголеми вредност
- Основни аритметички операции како што се собирање и множење
Да претпоставиме дека разгранувањето(изборот помеѓу if и else деловите од кодот откако if условот ќе биде евалуиран) се случува инстантно и дека нема да ги броиме овие инструкции. Во кодот горе, првата линија е:
var M = A[ 0 ];
За ова се потребни 2 инструкции: Една за барање на A[ 0 ] и една за доделување на вредност на M (претпоставуваме дека n е секогаш барем 1). Овие 2 инструкции се секогаш потребни на алгоритмот, без разлика на вредноста на n. Исто така кодот за иницијализација на for циклусот мора секогаш да се извршува. Ова ни дава уште 2 инструкции; за доделување и за споредба:
i = 0;
i < n;
Овие ќе се извршуваат пред првата итерација на for циклусот. После секоја итерација на for циклусот, ни требаат уште 2 инструкции, една за инкрементот на i и една за споредба да провери дали треба да останеме во лупата:
++i;
i < n;
Така, ако го игнорираме кодот што треба да се изврши внатре во циклусот, бројот на инструкциите потребни за овој алгоритам се 4+2n. Значи, 4 инструкции на почетокот на for циклусот и 2 инструкции на крајот на секоја итерација и заради тоа имаме n. Сега може да дефинираме математичка функција f(n) која, за дадено n, ќе ни го даде бројот на инструкции потребни за овој алгоритам. За празен for циклус, имаме f( n ) = 4 + 2n.
Анализа на најлош случај
Сега, гледајќи го for циклусот, имаме операција за пребарување на низа и споредба која се случува секогаш кога:
if ( A[ i ] >= M ) { ...
Тоа се две инструкции. Но кодот во if условот може да се изврши или може да не се изврши, зависно од вредностите на низата. Ако се случи да биде A A[ i ] >= M, тогаш ова ќе изврши дополнителни 2 инструкции - барање во низата и едно доделување:
M = A[ i ]
Но, сега не можеме да ја дефинираме f(n) така едноставно, затоа што бројот на инструкции не зависи само од n, туку и од нашиот влез. На пример, за A = [ 1, 2, 3, 4 ] на алгоритмот ќе му треба повеќе инструкции отколку за A = [ 4, 3, 2, 1 ]. Кога го анализираме алгоритмот, најчесто го земаме сценариото на најлош случај. Што е најлошото што може да му се случи на нашиот алгоритам? Кога на нашиот алгоритам ќе му требаат најмногу инструкции за да се изврши комплетно? Во овој случај, тоа ќе биде кога имаме низа во растечки редослед како A = [ 1, 2, 3, 4 ]. Во тој случај, M треба да се замени секогаш и тоа доведува до најголем број на инструкции. Информатичарите имаат елегантно име за тој случај и го викаат анализа на најлош случај; тоа не е ништо различно од земање во предвид случајот кога сме најмногу немаме среќа. Значи, во најлош случај, ќе имаме 4 инструкции да се извршуваат во for циклусот, па имаме f( n ) = 4 + 2n + 4n = 6n + 4. Оваа функција f, за дадена вредност n, ќе ни го даде бројот на инструкции кои би биле потребни во најлошиот случај.
Асимптотско однесување
Ако ни е дадена таква функција, може многу добро да определиме колку е брз нашиот алгоритам. Но, како што ветив, нема да има потреба да одиме низ макотрпната задача на броење на инструкциите на нашиот проблем. Покрај тоа, бројот на инструкциите на CPU-то потребни за секој програмски јазик зависи од компајлерот на тој програмски јазик и од достапното инструкциско множество на CPU-то(пример, зависно дали е AMD или Intel Pentium на вашиот PC, или MIPS процесор на вашиот PlayStation 2) и рековме дека ќе го игнорираме тоа. Сега ќе ја извршиме нашата функција “f” низ еден “филтер” кој ќе ни помогне да се ослободиме од тие ситни детали кои информатичарите преферираат да ги игнорираат.
Во нашата функција, 6n +4, имаме 2 дела: 6n и 4. Во анализа на сложеноста ние се грижиме само за тоа што ќе и се случи на функцијата која ги брои инструкциите како што влезот на програмот (n) ќе се зголемува. Ова оди паралелно со претходната идеја за однесување на “сценарио на најлош случај” . Ние се интересираме за тоа како нашиот алгоритам ќе се однесува кога е третиран лошо; кога има предизвик да направи нешто тешко. Забележете дека ова е навистина корисно при споредување на алгоритми. Ако еден алгоритам победи друг за поголем влез, најверојатно е точно дека побрзиот алгоритам останува побрз кога ќе му дадеме полесен, помал влез. Од деловите на функцијата што ги земавме, ќе ги отфрлиме деловите кои растат споро и ќе ги задржиме оние кои растат брзо како што n станува поголем. Јасно е дека 4 останува 4 како што n расте, но 6n расте се поголемо и поголемо, и тежнее да е од поголема важност за поголеми проблеми. Така, првата работа што ќе ја направиме е да го отфрлиме 4 и да ја задржиме функцијата како f( n ) = 6n.
Ова има смисла ако размислите за тоа, бидејќи 4 е само иницијализирачка константа. Различни програмски јазици може да побаруваат различно време за подготовка. На пример, на Java и треба некое време за да ја иницијализира нејзината виртуелна машина . Бидејќи ги игнорираме разликите меѓу програмските јазици, единствено што логично е да ја игнорираме оваа вредност.p>
Втората работа што ќе ја игнорираме е константата пред n, па така нашата функција ќе постане f( n ) = n. Како што можете да забележите, ова многу ги олеснува работите. Има некоја смисла да ја отфрлиме константата пред n ако размислиме за тоа колку различно програмските јазици компајлираат. Пребарувањето на низата во еден јазик може да се компајлира со различни инструкции во различни програмски јазици. На пример, во C, извршувањето на A[ i ] не вклучува проверка дали i е во границите на декларираната големина на низа, додека во Pascal тоа е вклучено. Така, следниот код во Pascal:
M := A[ i ]
Е еквивалентно на следното во С:
if ( i >= 0 && i < n ) {
M = A[ i ];
}
Па така разумно е да очекуваме дека различни програмски јазици ќе иницира различни фактори кога ќе ги броиме нивните инструкции. Во нашиот пример во кој користиме прост Pascal компајлер кој е несвесен за можните оптимизации, на Pascal му требаат 3 инструкции за секој пристап до низата, за разлика од С, на кој му треба 1 инструкција. Отфрлувањето на овој фактор оди паралелно со игнорирањето на разликите меѓу различни програмски јазици и компајлери, за само да ја анализираме идејата на алгоритмот.
Филтерот “отфрлување на сите фактори” и “задржување на делот што најбрзо расте” како што е објаснето погоре е тоа што го нарекуваме асимптотско однесување. Така, асимптотското однесување на f( n ) = 2n + 8 е опишано од функцијата f( n ) = n. Математички гледано, она што го кажуваме овде е дека сме заинтересирани за границата на функцијата f како што n тежи кон бесконечност; но ако не разбирате што значи оваа фраза, не грижете се, бидејќи тоа е се што треба да знаете.( Како забелешка, во строги математички услови, не би можеле да ги отфрлиме константите во границата; но за информатички цели, сакаме да го направиме тоа поради горенаведените причини.) Да погледнеме неколку примери за да се запознаеме со овој концепт.
Да го најдеме асимптотското однесување на следните примери со отфрлање на константите и задржување на делот што расте најбрзо.
f( n ) = 5n + 12 дава f( n ) = n.
Со користење на истата аналогија како горенаведеното.
f( n ) = 109 дава f( n ) = 1.
Го отфрламе множителот 109*1, но сепак мора да ставиме вредност 1 за да покажеме дека оваа функција има не-нулта вредност.
f( n ) = n2 + 3n + 112 дава f( n ) = n2
Овде, n2 расте многу побрзо од 3n за доволно големо n, и затоа и го земаме.
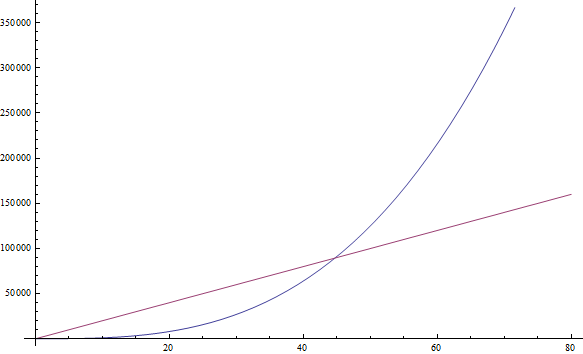
f( n ) = n3 + 1999n + 1337 дава f( n ) = n3
Иако факторот пред n е доста голем, сепак можеме да најдеме доволно големо n за кое n3 ќе е поголемо од 1999n. Бидејќи сме заинтересирани за однесувањето за многу големи вредности за n, ќе го задржиме само n3 (Види Фигура 2).
f( n ) = n +
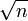 дава f( n ) = n
дава f( n ) = nОва е така затоа што n расте побргу од
како што n се зголемува.
Можете сами да ги пробате следниве примери:
Вежба 1
- f( n ) = n6 + 3n
- f( n ) = 2n + 12
- f( n ) = 3n + 2n
- f( n ) = nn + n
(Запишете ги вашите резултати; решението е дадено подолу)
Ако имате проблеми со некои од вежбите, само заменете го n со некоја голема бројка и видете кој дел е поголем. Доста лесно, нели?
Сложеност
Значи, ова ни кажува дека штом ќе ги отфрлиме сите овие украсни константи, станува доста едноставно да го видиме асимптотското однесување на функцијата за броење на инструкциите на еден програм. Всушност, секој програм кој нема циклуси ќе има f(n)=1, бидејќи потребниот број на инструкции е константа(освен ако не користи рекурзија; види подолу). Секој програм со еден циклус кој оди од 1 до n ќе има f(n)=n, затоа што ќе извршува константен број на инструкции пред циклусот, константен број на инструкции после циклусот и константен број на инструкции за време на циклусот кои сите се извршуваат n пати.
Сега, ова би требало да е многу полесно и не толку досадно, за разлика од броењето на индивидуални инструкции, па да разгледаме неколку примери за да се запознаеме со ова. Следниот PHP програм проверува дали одредена вредност постои во низа А со големина n:
<?php
$exists = false;
for ( $i = 0; $i < n; ++$i ) {
if ( $A[ $i ] == $value ) {
$exists = true;
break;
}
}
?>
Овој метод на пребарување на низа за дадена вредност се нарекува линеарно пребарување. Ова име си има своја позадина, затоа што програмот има f( n ) = n (во наредната секција ќе дефинираме поточно што значи “линеарно”). Можете да забележите дека има “break” израз кој што може порано да го заврши програмот, дури и после една итерација. Но, потсетете се дека се интересираме за сценариото на најлош случај, кое за овој програм би било низата А да не ја содржи бараната вредност. Значи, сепак имаме f( n ) = n;
Вежба 2
Систематски го анализираме бројот на инструкции што на погорниот PHP програм ќе му требаат земено дека n е најлош можен случај за да го најдеме f( n ),слично како што го анализиравме нашиот прв Javascript програм. Потоа видете дека, асимптотски, имаме f( n ) = n.
Да погледнеме програм во Python кој додава 2 елементи од низа за да направи сума која ја зачувува во друга променлива:
v = a[ 0 ] + a[ 1 ]
Овде имаме константен број на инструкции, па ќе имаме f( n ) = 1.
Следниот код во С++ проверува дали еден вектор(елегантна низа) наречен А со големина n содржи исти вредности било каде во него:
bool duplicate = false;
for ( int i = 0; i < n; ++i ) {
for ( int j = 0; j < n; ++j ) {
if ( i != j && A[ i ] == A[ j ] ) {
duplicate = true;
break;
}
}
if ( duplicate ) {
break;
}
}
Бидејќи овде имаме 2 вгнездени циклуси еден во друг, ќе имаме асимптотско однесување опишано од f( n ) = n2.
Правило на палец: Едноставни програми можат да се анализираат со броење на вгнездените циклуси во нив. Едноставен циклус за n вредности ќе доведе до f( n ) = n. Циклус во циклус доведува до f( n ) = n2. Циклус во циклус во циклус доведува до f( n ) = n3.
Ако имаме програм кој повикува функција во циклус и го знаеме бројот на инструкции кои дадената функција ги извршува, лесно е да се определи бројот на инструкции на целиот програм. Навистина, да го разгледаме следниот пример во С:
int i;
for ( i = 0; i < n; ++i ) {
f( n );
}
Ако знаеме дека f ( n ) е функција која извршува точно n инструкции, тогаш можеме да знаеме дека бројот на инструкции на целиот програм е асимптотички n2, бидејќи функцијата е повикана точно n пати.
Правило на палец : За дадена серија од циклуси кои се последователни, најспората од нив го одлучува асимптотското однесување на програмот. Два вгнездени циклуси проследени со еден циклус се асимптотски исти со вгнездените циклуси, затоа што вгнездените циклуси го доминираат обичниот циклус.
Сега, да се префрлиме на модерната нотација која информатичарите ја користат. Кога асимптотички ќе ја откриеме таквата f, можеме да кажеме дека нашиот програм е Θ( f( n ) ). На пример, погорните програми се Θ( 1 ), Θ( n2 ) и Θ( n2 ) соодветно. Θ( n ) се изговара “тета од n”. Понекогаш кажуваме дека f( n ), оригиналната функција која ги брои инструкциите и константите, е Θ( од нешто ). На пример, можеме да кажеме дека f( n ) = 2n е функција која е Θ( n ) — ништо ново овде. Исто така, може да напишеме 2n ∈ Θ( n ), што се изговара “2n е тета од n”. Нека не ве буни оваа нотација: Се што кажува е дека ако сме го изброиле бројот на инструкциите кои на еден програм му се потребни и изнесува 2n, тогаш асимптотското однесување на нашиот алгоритам ќе биде опишано од n, кое го најдовме со отфрлање на константите. Со оваа нотација, точни се следните математички изрази:
- n6 + 3n ∈ Θ( n6 )
- 2n + 12 ∈ Θ( 2n )
- 3n + 2n ∈ Θ( 3n )
- nn + n ∈ Θ( nn )
Патем, ако ја решивте Задача 1 од погоре, овие се одговорите кои би требало да ги добиете.
Ова го нарекуваме функција, т.е она што го ставаме Θ( овде ) е, временската сложеност, или само сложеноста на нашиот алгоритам. Така, алгоритам со Θ( n ) има сложеност n. Имаме и специјални имиња за Θ( 1 ), Θ( n ), Θ(n2 ) и Θ( log( n ) затоа што се појавуваат многу често. За Θ( 1 ) алгоритмите велиме дека се временски-константни алгоритми, Θ( n ) е линеарен, Θ(n2 ) е квадратен и Θ( log( n ) ) е логаритамски ( не грижете се ако сеуште не знаете што се тоа логаритми - ќе дојдеме до тоа за некоја минутка).
Правило на палец: Програми со поголемо Θ се извршуваат поспоро отколку програмите со помало Θ.

Големо-О нотација
Сега, понекогаш е точно дека е тешко да се одреди точното однесување на алгоритмот со овие методи кои ги користевме досега, поготово за посложени примери. Но, ќе можеме да кажеме дека однесувањето на нашиот алгоритам никогаш нема да надмине одредена граница. Ова ќе ни го олесни животот, затоа што не мора точно да специфицираме колку брзо ќе се извршува нашиот алгоритам, дури и кога ги игнорираме константите на начинот како што направивме претходно. Се што треба да направиме е да најдеме одредена граница. Ова лесно се објаснува со пример.
Познат проблем што информатичарите го користат за да предаваат алгоритми е проблемот на сортирање. Во проблемот на сортирање, дадена е низа А со големина n(ви звучи познато?) и се бара од нас да напишеме програм кој ќе ја сортира оваа низа. Овој проблем е интересен бидејќи е прагматичен проблем во реални системи. На пример, еден file explorer треба да ги сортира по име фајловите што ги прикажува, така што корисникот може да ги управува со леснотија. Или, друг пример, видео игра ќе треба да сортира 3D објекти прикажани во светот базирано на нивната оддалеченост од окото на играчот внатре во виртуелниот свет со цел да одлучи што е видливо и што не е, нешто наречено Проблем на видливост (see Фигура 3). Објектите што излезе дека се најблиску до играчот се тие видливите, додека оние што се подалеку може да бидат скриени од објектите пред нив. Сортирањето е, исто така, интересно бидејќи постојат многу алгоритми за да се реши, некои подобри, а некои полоши од другите. Исто така претставува едноставен проблем за дефинирање и објаснување. Затоа, да напишеме дел од код кој сортира низа.
Еве еден неефикасен начин да се имплементира сортирање на низа во Ruby. (Секако, Ruby подржува сортирање на низи користејќи вградени функции кои би требало да ги користиме, и кои сигурно се побрзи од ова што ќе го видиме тука. Но, ова е само како пример.)
b = []
n.times do
m = a[ 0 ]
mi = 0
a.each_with_index do |element, i|
if element < m
m = element
mi = i
end
end
a.delete_at( mi )
b << m
end
Овој метод се вика selection sort. Го наоѓа минимумот на нашата низа( низата е погоре е означена како а, додека минимумот како m и mi како негов индекс), го става на крајот на ноа низа(во нашиот случај b), и го отстранува од од матичната низа. Потоа го наоѓа минимумот од останатите вредности на матичната низа, го додава на новата низа така што сега содржи 2 елементи, и го отстранува од матичната низа.Овој процес трае се додека сите елементи не бидат отстранети од матичната низа и бидат ставени во новата низа, што значи дека низата е сортирана. Во овој пример, гледаме дека имаме 2 вгнездени циклуси. Надворешниот циклус се извршува n пати, и внатрешниот циклус се извршува еднаш за секој елемент од низата а. Додека низата а почетно има n елементи, отстрануваме еден елемент во секоја итерација. Така што внатрешниот циклус се повторува n пати за време на првата итерација на надворешниот циклус, потоа n-1 пати, потоа n-2 пати итн., се до последната итерација на надворешниот циклус каде се извршува само еднаш..
Малку е потешко да се евалуира сложеноста на овој програм, бидејќи би требало да ја определиме сумата 1+2+...+(n-1)+n. Но, со сигурност можеме да најдеме горна граница за него. Така што, може да го измениме нашиот програм(може да го направите во вашиот ум, не во кодот) да го направите полош отколку што е и тогаш да ја најдеме сложеноста на тој нов програм. Ако можеме да ја најдеме сложеноста на полошиот програм што сме го конструирале, тогаш ќе знаеме дека нашиот оригинален програм е најмногу толку лош, или пак подобар. На тој начин, ако најдеме добра сложеност за нашиот изменет програм, кој е полош од оригиналот, ќе можеме да знаеме дека нашиот оригинален програм ќе има исто така добра сложеност - или добра како нашиот изменет програм или пак уште подобра.
Сега, да најдеме начин да го измениме овој програм за да полесно да ја откриеме неговата сложеност. Но, имајте во предвив дека можеме и да го направиме полош, т.е да му треба повеќе инструкции, така што нашата проценка е битна за нашиот оригинален програм. Можеме да го измениме внатрешниот циклус на програмот секогаш да се повторува точно n пати, наместо различен број на пати. Некои од овие повторувања ќе бидат безначајни, но тоа ќе ни помогне да ја анализираме сложеноста на резултантниот алгоритам. Ако ја имплементираме оваа мала измена, тогаш новиот алгоритам што сме го создале е Θ( n2 ), затоа што имаме 2 вгнездени цилуси од кои секој се повторува точно n пати. Ако е тоа така, можеме да кажеме дека оригиналниот алгоритам е O( n2 ). O( n2 ) се изговара”големо о од n на квадрат”. Ова ни кажува дека нашиот програмски асимптотски гледано не е полош од n2 .Може да биде дури и подобар од тоа, или може да биде ист.Патем, ако нашиот програм е навистина Θ( n2 ) , сеуште можеме да кажеме дека е О(n2). Мала помош, замислете дека го изменуваме нашиот програм на тој начин што не менуваме многу, но сепак го правиме малку полош, додавајќи непотребни инструкции на почетокот на програмот. Со ова, ќе ја измениме функцијата за броење на инструкции за една константа, која ја игнорираме кога станува збор за асимптотско однесување. Така, програм кој е Θ( n2 ) исто така е и O( n2 ).p> n2
Но, програм кој е O( n2 ) немора да биде и Θ( n2 ). На пример, програм што е Θ( n ) е исто така и O( n2 ), покрај тоа што е O( n ). Ако замислиме дека Θ( n ) програм е прост for циклус кој се повторува n пати, можеме да го направиме полош ако го вметнеме во друг for циклус кој исто така се повторува n пати, произведувајќи програм со f( n ) = n2. Да го обопштиме ова, секој програм што е Θ( a ) e O( b ), кога b е полошо од a. Забележете дека нашата измена на програмот не мора да ни даде програм кој ќе е значаен или еквивалентен на нашиот оригинален програм. Тој само мора да изведе повеќе инструкции од оригиналниот за дадено n. Го употребуваме само за да броиме инструкции, а не да го решиме нашиот проблем.
Значи, земајќи дека нашиот програм кој е O( n2 ) е на сигурната страна: Го анализиравме нашиот алгоритам, и најдовме дека никогаш неможе да биде полош од n2 . Но, може да биде и до тоа што тој е всушност n2. Ова ни дава добра проценка за тоа колку брзо нашиот алгоритам се извршува. Да погледнеме неколку примери кои ќе ни помогнат да се запознаеме со оваа нотација.
Вежба 3
Пронајди кои од следниве се точни:
- Алгоритмот Θ ( n ) е O( n )
- Aлгоритмот Θ( n ) е O( n2 )
- Aлгоритмот Θ( n2 ) е O( n3 )
- Aлгоритмот Θ( n ) е O( 1 )
- Aлгоритмот O( 1 ) е Θ( 1 )
- Aлгоритмот O( n ) е Θ( 1 )
Решение
- Знаеме дека ова е точно ако нашиот оригинален програм бил Θ( n ). Можеме да го достигнеме О(n) без било какви модификации на нашиот програм.
- Бидејќи n2 е полошо од n, ова е точно.
- Бидејќи n3 е полошо од n2, ова е точно.
- Бидејќи 1 не е полошо од n, ова е погрешно. Ако еден програм зема n инструкции(линеарен број на инструкции), не можеме да го направиме полош и да зема само 1 инструкција(константен број на инструкции).
- Ова е точно само ако 2-те сложеност се исти.
- Ова може да е точно, но и не мора да значи, зависно од нашиот алгоритам. Обично е погрешно. Ако еден алгоритам е Θ(1), тогаш тој со сигурност е O(n). Но ако е О(n) тогаш може да не е Θ(1). На пример, еден Θ( n ) алгоритам е О(n) но не Θ( 1 ).
Вежба 4
Користете сума со аритметичка прогресија за да докажете дека погорниот програм не е само O( n2 ) туку и Θ( n2 ). Ако не знаете што е аритметичка прогресија, погледнето на Wikipedia – лесно е.
Поради тоа што О-сложеноста на еден алгоритам ја дава горната граница на реалната сложеноста на тој алгоритам, додека Θ ја дава реалната сложеност на тој алгоритам, понекогаш велиме дека Θ ни дава тесна граница. Ако знаеме дека сме нашле граница на сложеност која не е тесна, можеме да користиме мало о за да го означиме тоа. На пример, ако еден алгоритам е Θ(n), тогаш неговата тесна сложеност е n. Тогаш овој алгоритам е и О(n) и O(n2). Бидејќи алгоритамот е Θ(n), О(n) границата е тесна. Но O(n2) границата не е тесна, па така може да напишеме дека алгоритамот е о(n2), кое се изговара “мало о од н на квадрат” за да покажеме дека знаеме дека нашата граница не е тесна. Добро е ако можеме да најдеме тесни граници за нашите алгоритми, бидејќи тие ни даваат повеќе информации за тоа како нашиот алгоритам се однесува, но тоа не е секогаш лесни да се направи.
Вежба 5
Определете кои од следниве граници се тесни, а кои не. Проверете дали некои граници се погрешни. Користете о(нотација) за да покажете дека не се тесни.
- За Θ( n ) алгоритмот имаме O( n ) како горна граница.
- За Θ( n2 ) алгоритмот имаме O( n3 ) како горна граница.
- За Θ( 1 ) ) алгоритмот имаме O( n ) како горна граница.
- За Θ( n ) ) алгоритмот имаме O( 1 ) како горна граница.
- За Θ( n ) ) алгоритмот имаме O( 2n ) како горна граница.
Решение
- Во овој случај, Θ-сложеноста и О-сложеноста се исти, па границата е точна.
- Овде можеме да видиме дека О-сложеноста е од поголем степен од Θ-сложеноста, па оваа граница не е тесна. Навистина, граница со О(n2 ) е тесна. Па така пишуваме дека алгоритамот е о( n3 ).
- Повторно гледаме дека О-сложеноста е од поголем степен од Θ-сложеноста, и пак имаме граница која не е тесна. Границата на О(1) би била тесна. Па, покажуваме дека границата О(n) не е тесна со пишување о(n).
- Мора да сме направиле грешка при пресметувањето на оваа границта, бидејќи е погрешна. Невозможно е за Θ( n ) алгоритам да има горна граница од О(1), бидејќи n има поголема сложеност од 1. Запамтете дека О ја дава горната граница.
- Оваа граница може да изгледа како граница што не е тесна, но тоа, всушност, не е точно. Оваа граница е тесна. Потсетете се дека асимптотското однесување на 2n и n е исто, и дека О и Θ се интересираат само за тоа. Значи, имаме O( 2n ) = O( n ), и според тоа оваа граница е тесна бидејќи сложеноста е иста како и Θ.
Правило на палец: Полесно е да се воочи О-сложеноста на еден алгоритам отколку неговата Θ-сложеност.
Moжеби ве преоптоварив со сите овие нотации, но да видиме само уште 2 симбола пред да преминеме на следните вежби. Овие се лесни сега кога ги знаеме Θ, O и o, и нема да ги користиме многу во оваа статија, но добро е да се знаат штом веќе сме дошле до тука. Во примерот погоре, ја изменивме нашата програма за да ја направиме полош(т.е да му требаат повеќе инструкции и со тоа повеќе време) и воведовме О-нотација. О е значајно затоа што ни кажува дека нашата програма никогаш нема да биде поспора од некоја граница, и со тоа ни дава вредна информација со што можеме да потврдиме дека нашата програма е доволно добара. Ако го направиме спротивното и го измениме нашиот код за да ја направиме подобра и да ја најдеме сложеноста на таа програма, тогаш ја користиме нотацијата Ω. Ω ни ја дава сложеноста од која нашата програма нема да биде подобра. Ова е корисно ако сакаме да докажеме дека некоја програма се извршува споро или еден алгоритам не е добар. Ова може да биде корисно за да се потврди дека еден алгоритам е премногу спор за да се користи во одреден случај. На пример, ако земеме дека еден алгоритам е Ω(n3 ), тоа значи дека алгоритмот не е подобар од n3. Може да е Θ( n3), лош како Θ( n4) или пак уште полош, но знаеме дека е во најмалку лош. Така Ω ни ја дава долната граница на сложеноста на нашиот алгоритам. Слично како о, можеме да напишеме ω ако знаеме дека нашата граница не е тесна. На пример, алгоритмот Θ( n3) е о( n4) и ω( n2). Ω( n ) се изговара ”големо омега од n” , додека и ω( n ) се изговара “мало омега од n”p>
Вежба 6
За следниве сложености Θ напишете тесна и не-тесна граница О, и тесна и не-тесна граница Ω, по избор, земајќи дека постојат.
- Θ( 1 )
- Θ( )
- Θ( n )
- Θ( n2 )
- Θ( n3 )
Решение
Ова е директна примена на погорните дефиниции.
- Тесната граница ќе биде О(1) и Ω(1). Не-тесната граница О ќе биде О(n). Потсетете се дека О ни ја дава горната граница. Бидејќи n е со поголем степен од 1 ова е не-тесна граница и ја пишуваме како о(n). Но, не можеме да најдеме не-тесна граница за Ω, бидејќи не можеме да одиме подолу од 1 за овие функции. Па така ќе земеме тесна граница.
- Тесните граници ќе мораат да бидат исти како и Θ-сложеноста, па така ти се O( ) и Ω( ) соодветно. . За не-тесни граници ќе имаме О(n), бидејќи n е поголем од е исто така и горна граница за . Бидејќи знаеме дека ова е не-тесна граница, ја пишуваме како о(n). За долната граница која не е тесна, едноставно користиме Ω(1). Бидејќи знаеме дека оваа граница не е тесна, ја пишуваме како ω( 1 ).
- Тесните граници се O( n ) и Ω( n ). Двете не-тесни граници можат да бидат ω( 1 ) и o( n3 ). Овие всушност се доста лоши граници, бидејќи се далеку од оригиналната сложеност, но се сеуште валидни користејќи ги нашите дефиниции.
- Тесните граници се O( n2) и Ω( n1). За не-тесни граници повторно би можеле да употребиме ω( 1 ) и o( n3) како во претходниот пример.
- Тесните граници се O( n3 ) и Ω( n3 ) соодветно. Двете не-тесни граници можат да бидат ω( n2) и o( n3 ). Иако овие граници не се тесни, тие се подобри од оние што ги наброивме погоре.
.
Причината поради која користиме O и Ω наместо Θ иако O и Ωисто така можат да дадат тесни граници е поради тоа можеби нема да бидеме во можност да кажеме дали некоја граница е тесна, или пак едноставно не би сакале да одиме низ процесот да ја истражуваме премногу.
Ако не се сеќавате потполно на сите различни симболи и за што служат, не грижете се сега премногу за тоа. Секогаш може да се вратите назад и да ги побарате. Најважните симболи се O и Θ.
Исто така забележете дека иако Ω ни го дава долното гранично однесување на нашата функција(т.е сме ја подобриле нашата програма и таа извршува помалку инструкции) ова сеуште се однесува на анализата на најлош случај. Ова е така затоа што на нашата програма и го даваме најлошиот можен влез за дадено n и го анализираме нејзиното однесување под оваа претпоставка.
Следната табела ги покажува симболите кои ги воведовме и нивната кореспонденција со обичните математички симболи за споредба што ги користиме за броеви. Причината поради која овде не ги користиме секојдневните симболи и наместо тоа користиме грчки букви е да покажеме дека правиме споредба на асимптотско однесување, а не само обична споредба.
| Оператор за асимптотска споредба | Оператор за нумеричка споредба |
|---|---|
| Нашиот алгоритам е o( од нешто) | Бројот е < од нешто |
| Нашиот алгоритам е O( од нешто) | Бројот е ≤ од нешто |
| Нашиот алгоритам е Θ( од нешто) | Бројот е = од нешто |
| Нашиот алгоритам е Ω( од нешто) | Бројот е ≥ од нешто |
| Нашиот алгоритам е ω( од нешто) | Бројот е > од нешто |
Правило на палец: Додека секој од симболите O, o, Ω, ω и Θ е корисен, О е оној кој најчесто се користи, бидејќи е полесен да се одреди од Θ и покорисен практично од Ω.
Логаритми
Ако знаете што се тоа логаритми, слободно може да го прескокнете овој дел. Бидејќи многу луѓе не се запознаени со логаритмите, или пак не ги користеле и ги заборавиле, овој дел ќе биде како вовед за нив. Овој текст е, истотака, и за помлади студенти кои досега на училиште не се сретнале со логаритмите. Логаритмите се важни затоа што се појавуваат често кога анализираме сложеност. Логаритам е операција извршена на број што го прави бројот доста помал - нешто слично на квадратен корен на број. Така, ако нешто треба да запомните за логаритмите е тоа дека земаат број и го прават многу помал од оригиналот(види Фигура 4). Сега, на ист начин како што квадратниот корен е инверзна операција од квадрирање на нешто, логаритмите се инверзна операција од експонентирање на нешто. Ова не е толку тешко како што звучи. Подобро се објаснува со пример. Да ја разгледаме равенката:
2x = 1024
Сега, треба да ја најдеме вредноста на x. И се прашуваме: Кој е бројот со кој треба да ја степенуваме основата 2 за да добиеме 1024? Одговорот е 10. Навистина, имаме 210= 1024, што е лесно да се провери. Логаритмите ни овозможуваат да го означиме овој проблем користејќи нова нотација. Во нашиот случај, 10 е логаритмот на 1024 и го пишуваме како log(1024) и го читаме како “логаритам од 1024”. Затоа што користиме 2 како основа, овие логаритми се нарекуваат логаритми со основа 2. Ако сте студент кој се натпреварува во интернационални натпревари и не знаете ништо за логаритмите, препорачувам да вежбате логаритми откако ќе го прочитате овој прилог. Во информатиката, логаритмите со основа 2 се многу повеќе застапени отколку било кои други типови на логаритми. Ова е така затоа што често имаме само 2 различни вредности: 0 и 1. Исто така, тежнееме да поделиме еден голем проблем на половина, од кој секогаш има 2 половини. Значи, треба само да знаете за логаритми со основа 2 за да продолжите да го читате овој прилог.
Вежба 7
Реши ги равенките подолу. Означи кој логаритам ќе го најдете за секоја од равенките. Користете само логаритам со основа 2.
- 2x = 64
- (22)x = 64
- 4x = 4
- 2x = 1
- 2x + 2x = 32
- (2x) * (2x) = 64
Решение
Нема ништо повеќе за ова од идеите дефинирани погоре.
- Со пробување можеме да најдеме дека x=6 и така log(64)=6.
- Овде можеме да забележиме дека (22)x, според својствата на експонентите, може да се запише како 22x. Така, имаме дека 2x=6, бидејќи oд претходниот резултат log(64)=6, односно x=3.
- Користејќи го нашето знаење од претходната равенка, можеме да го напишеме 4 како 22 и така нашата равенка постанува (22)x = 4 што е исто со 22x = 4. Забележуваме дека log( 4 ) = 2 затоа што 22 = 4 и оттука 2x = 2,односно x = 1. Ова се воочува лесно од оригиналната равенка, бидејќи користејќи експонент 1 ја добиваме базата како резултат.
- Сетете се дека експонент 0 дава резултат 1. Па имаме log( 1 ) = 0 како 20 = 1, па така и x = 0.
- Овде имаме сума и како таква не можеме директно да го одредиме логаритамот. Но, забележуваме дека 2x+ 2x е исто како и 2 * (2x). Така добиваме производ од уште 2, и нашата равенка постанува 2x+1 и сега се што треба да направиме е да ја решиме равенката 2x+1= 32. Наоѓаме дека log(32) = 5, па така x+1=5, односно x=4.
- Множиме 2 степена на 2, и како такви можеме да забележиме дека (2x)*(2x)е исто со 22x. Потоа се што треба да направиме е да ја решиме равенката 22x. = 64, која веќе ја решивме погоре како x=3.
Правило на палец: За натпреварот по алгоритмите имплементирани во C++, откако ќе ја анализирате вашата сложеност, можете да добиете груба пресметка за тоа колку брзо се извршува вашата програма очекувајќи да изврши околу 1,000,000 операции во секунда, каде што операциите што ги броите се дадени од функцијата за асимптотското однесување која го опишува вашиот логаритам. На пример, на Θ( n ) алгоритам му треба околу 1 секунда за да процесира влез за n=1,000,000.
Рекурзивна сложеност
Да погледнеме една рекурзивна функција. Рекурзивна функција е функција која се повикува себеси. Дали можеме да ја анализираме нејзината сложеност? Следната функција, напишана во Python, пресметува факториел на даден број. Факториел е позитивен цел број кој се добива кога ќе се помножи заедно со сите негови претходни позитивни цели броеви. На пример, факториел од 5 е 5 * 4 * 3 * 2 * 1. Го означуваме како “5!” и го изговараме “факториел од пет”(некои луѓе преферираат да го изговараат викајќи гласно “ПЕТ!!!”)
def factorial( n ):
if n == 1:
return 1
return n * factorial( n - 1 )
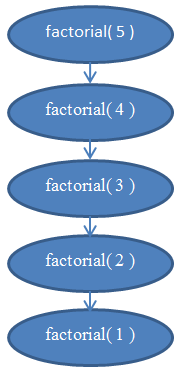
Сега, да ја анализираме сложеноста на оваа функција. Оваа функција нема циклуси во неа, но истотака, и нејзината сложеност не е константна . За да ја најдеме сложеноста на оваа функција пак треба да броиме инструкции. Очигледно е дека за дадено n, оваа функција ќе се извршува n пати. Ако не сте сигурни за тоа, извршете ја “рачно” за n=5 за да ви стане јасно дека е така. На пример, за n=5, ќе се изврши 5 пати, бидејќи ќе се намалува за 1 со секој повик. Оттука можеме да видиме дека оваа функција е Θ( n ).
Ако не сте сигурни за овој факт, запомнете дека секогаш можете да ја најдете точната сложеност со броење на инструкциите. Ако сакате, може да се обидете да ги броите инструкциите извршени од оваа функција за да најдете функција f(n) и за да видите дека таа навистина е линеарна(потсетете се дека линеарно значи Θ( n )).
Види ја Фигура 5 за дијаграм кој ќе ви помогне да ја разберете рекурзијата која се извршува кога факториел од 5 е повикан.
Ова треба ви да разјасни зошто оваа функција има линеарна сложеност.
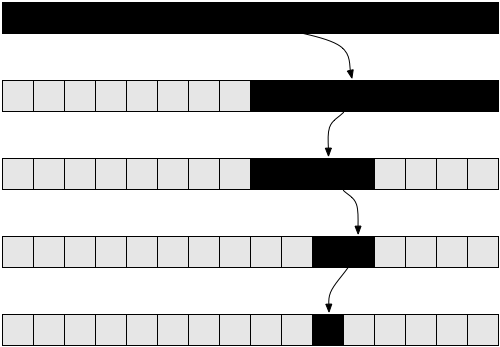
Сложеност на логаритми
Познат проблем во компјутерската наука е проблемот да се најде вредност во една низа. Ова беше решено претходно за општ случај. Проблемот станува интересен кога имаме сортирана низа и сакаме да најдеме дадена вредност во неа. Еден од методите да се направи ова е наречен бинарно пребарување. Го бараме елементот во средниот дел од низата; ако е таму,сме завршиле. Во спротивно, доколку вредноста која сме ја нашле таму е поголема од вредноста која ја бараме, знаеме дека нашиот елемент ќе биде на левата страна од низата, или во спротивно, на десната страна од низата. Можеме да продолжиме со делење на овие помали низи на половини се додека не добиеме еден елемент. Ова е методот користејќи псевдокод :
def binarySearch( A, n, value ):
if n = 1:
if A[ 0 ] = value:
return true
else:
return false
if value < A[ n / 2 ]:
return binarySearch( A[ 0...( n / 2 - 1 ) ], n / 2 - 1, value )
else if value > A[ n / 2 ]:
return binarySearch( A[ ( n / 2 + 1 )...n ], n / 2 - 1, value )
else:
return true
Овој псевдокод е поедноставување на вистинското имплементирање. Во пракса, овој метод полесно се опишува отколку применува, бидејќи програмерот мора да се погрижи уште за некои проблеми при имплементирање. Постојат можни грешки и поделбата на 2 може не секогаш да даде целобројна вредност, такашто е потребно да се максимизира или минимизира вредноста. Но, можеме да претпоставиме за нашите намени дека секогаш ќе успее, и ќе претпоставиме дека имплементирањето ќе ги исправи можните грешки, бидејќи само ја анализираме сложеноста на овој метод. Доколку досега не сте спровеле бинарно пребарување, можеби ќе сакате да го направите ова во вашиот омилен програмски јазик. Ова е навистина корисен опит.
Погледнете ја Фигура 6 за да разберете како се извршува бинарното пребарување.
Доколку не сте сигурни дека овој метод функционира, пробајте да го спроведете рачно со едноставен пример и ќе се убедите дека всушност функционира.
Да се обидеме да го анализираме овој алгоритам. Повторно, имаме рекурзивен алгоритам во случајов. Да претпоставиме, поедноставено, дека низата е секогаш поделена точно на половина, игнорирајќи го само сега +1 и -1 делот во рекурзивниот повик. Досега треба да сте убедени дека мала промена како игнорирањето на +1 и -1, нема да влијае врз резултатите за сложеност. Вообичаено, би морале да докажеме доколку сакаме да сме внимателни од математичка гледна точка, но од практична гледна точка, очигледно е. Да претпоставиме дека нашата низа има големина што е степен на 2, поедноставено. Повторно оваа претпоставка нема да ги смени крајните резултати од сложеноста до која ќе стигнеме. Најлошата можна варијанта на проблемот би ја имале доколку вредноста која ја бараме воопшто не се јавува во низата. Во тој случај би започнале со низа со големина n во првиот рекурзивен повик, и би добиле низа со големина n/2 во следниот повик. Тогаш би добиле низа со големина n/4 во следниот рекурзивен повик, па низа со големина n/8 во следниот. Обопштено, со секој повик нашата низа е поделена на половина, се додека не стигнеме до 1 елемент. Да го напишеме бројот елементи во нашата низа за секој повик:
Во i-тата итерација, нашата низа има n / 2i елементи. Ова се должи на тоа што во секоја итерација ја делиме нашата низа на половина, т.е го делиме бројот на елементи на два. Ова води до множење на именителот со 2. Ако го направиме тоа i пати, добиваме n / 2i. Постапката продолжува и со секое поголемо i добиваме помал број на елементи додека не дојдеме до последната итерација во која имаме само еден преостанат елемент. Доколку сакаме да го најдеме i да видиме во која итерација тоа се случува, мораме да ја решиме следната равенка :
1 = n / 2i
Ова ќе се постигне единствено кога ќе стигнеме до последниот повик во функцијата од бинарното пребарување, не за општ случај. Решението на i ќе ни помогне да најдеме во која итерација ќе заврши рекурзијата. Со множење на двете страни со 2i добиваме:
2i = n
Равенката ќе биде позната доколку го прочитате пасусот за логаритми горе. Решавајќи го i добиваме:
i = log( n )
Ова ни кажува дека потребниот број на повторувања за да се изведе бинарно пребарување е log( n ) каде n е број на елементи во оригиналната низа.
Доколку размислите, ова има смисла. На пример, земете n = 32 , низа од 32 елементи. Колку пати треба да ја поделиме на половина за да добиеме само само 1 елемент? Добиваме 32 →16 →8 →4 →2 →1. Го направивме ова 5 пати , кој е логаритам на 32. Според тоа, сложеноста на бинарното пребарување е Θ( log( n ) ).
Последниов резултат ни овозможува да го споредиме бинарното пребарување со линеарното, нашиот претходен метод. Очигледно, бидејќи log( n ) е многу помало од n, логично е да се заклучи дека бинарното пребарување е многу побрз метод за пребарување во состав на низа, отколку линеарното пребарување, поради што се советува низите да се оддржат сортирани доколку сакаме да пребаруваме во нивниот состав.
Правило на палец: Подобрување на асимптотското време на дејствување на програмите доста често значително го подобрува и нивниот резултат, многу повеќе од некои мали “технички” оптимизации како што е користењето на побрз програмски јазик.
Оптимално сортирање
Честитки. Вие сега знаете за анализата на сложеност на алгоритми, асимптотско однесување на функциите, и нотацијата “Големо О”. Исто така знаете интуитивно да откриете дека сложеноста на еден алгоритам е O( 1 ), O( log( n ) ), O( n ), O( n2 ) итн. Ги знаете симболите o, O, ω, Ω и Θ и што се подразбира под најлош случај на анализирање. Доколку сте дошле доовде, ова упатство веќе ја остварило својата намена.
Последниот пасус не е задолжителен. Малку е покомплициран, затоа можете да го прескокнете доколку ви предизвикува тешкотии. Ќе бара од вас да се фокусирате и да поминете низ вежбите. Меѓутоа, ќе ве обезбеди со многу корисен метод во анализата на сложеноста на алгоритми што може да биде многу важно, така што вреди да се разбере.
Досега разгледавме сортирачко имплементирање погоре т.н. селекциско сортирање. Спомнавме дека селекциското сортирање не е оптимално. Оптимален алгоритам е алгоритам кој решава проблем на најдобар можен начин, во смисла дека нема подобар алгоритам за тоа. Ова би значело дека сите останати алгоритми за решавање на проблемот имаат полоша или еднаква сложеност со тој оптимален алгоритам. Може да постојат повеќе оптимални алгоритми за еден проблем кои имаат иста сложеност. Проблемот со сортирање може да се реши оптимално на повеќе начини. Може да се користи истата идеја како кај бинарното пребарување за да се сортира брзо. Овој сортирачки метод е наречен сортирање со соединување (анг. mergesort).
За да се изврши mergesort најпрво мора да се изгради помошна функција која ќе се користи за да го изврши сортирањето. Ќе направиме функција на соединување
која зема две низи што се веќе сортирани и ги спојува во една голема сортирана низа. Ова лесно се изведува:
def merge( A, B ):
if empty( A ):
return B
if empty( B ):
return A
if A[ 0 ] < B[ 0 ]:
return concat( A[ 0 ], merge( A[ 1...A_n ], B ) )
else:
return concat( B[ 0 ], merge( A, B[ 1...B_n ] ) )
Функцијата за конкатенација зема предмет како “главен” и низа како “последен” и гради нова низа која го содржи “главниот” предмет како прв во новата низа и “последниот” како останатиот дел од елементите во низата. На пример, функцијата за конкатенација ( 3, [ 4, 5, 6 ] ) враќа [ 3, 4, 5, 6 ]. Користиме A_n и B_n за да ги обележиме големините на низите А и B, соодветно.
Вежба 8
Проверете дали горната функција изведува соединување. Препишете ја во вашиот омилен програмски јазик со итерации ( користејќи for циклуси ) наместо да користите рекурзија.
Анализирајќи го овој алгоритам откриваме дека има времетраење од Θ( n ), каде што n е должината на добиената низа (n = A_n + B_n).
Вежба 9
Проверете дали времето на извршување на соединувањето е Θ( n ).
Користејќи ја оваа функција можеме да создадеме подобар сортирачки алгоритам. Идејата е следната: Ja делиме низата на два дела. Го сортираме секој од двата дела рекурзивно, тогаш ги соединуваме двете сортирани низи во една голема низа. Во псевдокод :
def mergeSort( A, n ):
if n = 1:
return A # it is already sorted
middle = floor( n / 2 )
leftHalf = A[ 1...middle ]
rightHalf = A[ ( middle + 1 )...n ]
return merge( mergeSort( leftHalf, middle ), mergeSort( rightHalf, n - middle ) )
Oваа функција е потешка за разбирање од оние кои ги поминавме претходно, така што следната вежба можеби ќе ви одземе некое време.
Вежба 10
Проверете ја точноста на mergeSort, т.е. проверете дали mergeSort, како што е дефинирано погоре всушност точно ја сортира низата која му е дадена. Доколку имате потешкотии да разберете зошто функционира, обидете се со пример на мала низа и спроведете го тоа “рачно”. При тоа, осигурајте се дека десната и левата половина се она што ќе го добиете доколку ја поделите низата приближно на половина; не мора да биде точно во средина доколку низата има неправилен број на елементи ( за ова се користи floor погоре ).
Како последен пример, да ја анализираме сложеноста на mergeSort. Во секоја фаза на mergeSort, ја делиме низата на две половини со еднаква големина, слично како кај бинарното пребарување. Сепак, во овој случај, ги оддржуваме двете половини за време на извршувањето. Тогаш го применуваме алгоритмот рекурзивно во секоја половина. Откако рекурзијата завршува, ја применуваме операцијата на соединување врз резултатот за што е потребно Θ( n ) време.
Така, ја делиме првичната низа на две низи секоја со големина n / 2. Тогаш ги соединуваме тие низи, процес кој ги соединива n елементите и за што е потребно Θ( n ) време.
Погледнете ја Фигура 7 за да ја сфатите рекурзијата.
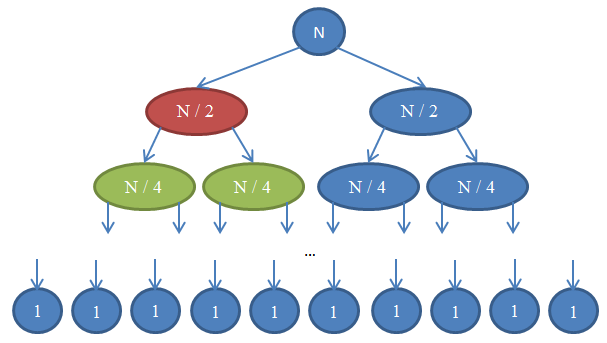
Да видиме што се случува овде. Секој круг претставува повик на функцијата mergeSort. Бројот впишан во кругот ја покажува големината на низата која се сортира. Горниот син круг е првичен повик на mergeSort, каде што сортираме низа со големина n. Стрелките означуваат рекурзивни повици помеѓу функциите. Првичниот повик на mergeSort прави два повици на mergeSort на две низи, секоја со големина n / 2. Ова е означено со двете низи на врвот. Следствено, секој од овие повици прави два свои повици на mergeSort на две низи, секоја со големина n / 4, итн, се додека не стигнеме до низа со големина 1. Овој дијаграм се нарекува рекурзивно дрво, бидејќи објаснува како рекурзијата се однесува и изгледа како дрво (коренот е на врвот и лисјата се на дното, така што ни изгледа како инверзно дрво).
Во секој ред во горниот дијаграм, вкупниот број на елементи е n. За да го забележите ова, погледнете го секој ред посебно. Првиот ред содржи само еден повик на mergeSort со низа со големина n , па вкупниот број на елементи е n. Вториот ред содржи два повика на mergeSort секој со големина n / 2. Но n / 2 + n / 2 = n и така повторно вкупниот број елементи е n. Во третиот ред има 4 повици од кои секој е применет на низа со големина n / 4 дозволувајќи вкупниот број на елементи да е еднаков на n / 4 + n / 4 + n / 4 + n / 4 = 4n / 4 = n. Повторно добиваме n елементи. Во секој ред од дијаграмот повикувачот мора да изврши соединување на елементите вратени од повиканите. На пример, кругот со црвена боја мора да сортира n / 2 елементи. За да го направи ова, ја дели низата со големина n / 2 на две низи со големина n / 4, повикува mergeSort рекурзивно да ги сортира (овие повици се зелените кругови), тогаш ги спојува заедно. Овој процес на соединување бара спојување на n / 2 елементи. Во секој ред од нашето дрво, вкупниот број на споени елементи е n. Во редот кој штотуку го разгледавме, нашата функција соединува n / 2 елементи и функцијата од десно (која што е со сина боја- исто така мора да соедини свои n / 2 елементи. Тоа налага вкупен број n елементи кои мора да се соединат за редот кој го разгледуваме.
Според тоа, сложеноста за секој ред е Θ( n ). Знаеме дека бројот на редови во дијаграмот, исто така наречен длабочина на рекурзивното дрво, ќе биде log( n ). Идејата за ова е истата што ја користевме анализирајќи ја сложеноста на бинарното пребарување. Имаме log( n ) редови и секој од нив е Θ( n ), оттаму сложеноста на mergeSort е Θ( n * log( n ) ). Ова е подобро од Θ( n2 ) што произлезе од селектирачкото сортирање(запамтете дека log( n ) е многу помало од n , па така n * log( n ) е многу помало од n * n = n2). Доколку ова ви звучи комплицирано, без паника: не e лесно кога го гледате првпат. Навратете се на овој пасус и препрочитајте го откако ќе имплементирате mergeSort во вашиот омилен програмски јазик и оцените како функционира.
Како што видовте во последниот пример,анализата на сложеност ни овозможува да ги споредиме алгоритмите и да видиме кој е подобар. Во вакви услови, можеме да сме доста сигурни дека mergeSort ќе го надмине selection sort за големи низи. Тешко ќе дојдевме до овој заклучок доколку не ја имавме теоретската основа за анализата на алгоритми која што ја развивме. Во пракса, навистина се користат сортирачки алгоритми со време на извршување Θ( n * log( n ) ). На пример, kernel-от на Linux користи сортирачки алгоритам наречен heapsort , кој го има истото време на извршување како и mergeSort кое што го истраживме овде, имено Θ( n log( n ) ) и е оптимално. Не докажавме дека овие сортирачки алгоритми се оптимални. За да се докаже тоа, потребен е посложен математички аргумент, но останатото укажува на тоа дека не можат да бидат подобри од гледна точка на сложеноста.
Откако завршивте со читање на ова упатство, интуицијата која ја развивте за анализата на сложеност на алгоритми треба да е доволна да ви помогне да развивате побрзи програми и да ги насочите вашите напори на важните прашања,наместо на ситни работи што не се битни, што ќе ви овозможи и да работите попродуктивно. Притоа, математичкиот јазик и нотација објаснети во овој напис како што е нотацијата “Големо О”, се од помош во комуникацијата со други софтверски инженери кога сакате да дискутирате за времето на извршување на алгоритмите, а со новостекнатото знаење тоа ќе може да го направите.
За статијата
Овој артикл е лиценциран под Creative Commons 3.0 Attribution. Ова значи дека може да се копира, сподели, објави на вашиот сопствен вебсајт, промени, и воглавно да се прави било што со него, под услов да се користи моето име. Иако не морате, доколку ја базирате вашaта работа на мојата, ве охрабрувам да ја објавите вашата сопствена работа под Creative Commons за да биде полесно за останатите да споделуваат и соработуваат исто така. По некое правило, морам да оддадам признание за мојата работа. Корисните икони кои ги гледате на оваа страна се fugue икони. Прекрасната пругаста рамка која што ја гледате во дизајнот е дело на Lea Verou. И најважно, алгоритмите кои ми беа потребни за да го напишам овој напис ги научив од мојот професор Dimitris Fotakis.
Моментално сум додипломец на факултетот за Електротехника и Компјутерско Инженерство при ржавниот Технички Универзитет во Атина специјализиран за софтвер и инструктор на грчки натпревари по информатика. Имам работено како член од тимот на инженери кои го создадоа deviantART, социјална мрежа за уметници, и два ангажмани во почетна фаза , Zino и Kamibu кадешто работиме на социјално мрежно поврзување и усовршување на видео игри. Следете ме на Тwitter или на github доколку ова ви се допадна или контактирајте ме на меил. Многу млади програмери немаат добро познавање на англискиот јазик. Пратете ми мејл доколку сакате да се преведе овој напис на вашиот мајчин јазик така што повеќе луѓе ќе можат да го прочитаат.
Ви благодарам за читањето. Не бев платен воопшто за да го напишам овој напис, па доколку ви се допадна, пратете ми меил само за да ме поздравите. Сакам да добивам слики од места низ светот, па слободно пратете ми слика од вас во вашиот град!
Фусноти
- Cormen, Leiserson, Rivest, Stein. Вовед во алгоритми, MIT Press.
- Dasgupta, Papadimitriou, Vazirani. Алгоритми, McGraw-Hill Press.
- Fotakis. Курс по Дискретна математика на државниот технички универзитет во Атина
- Fotakis. Курс по Алгоритми и сложеност на државниот технички универзитет во Атина

